你可能在很多地方见过 Parquet /pɑːrˈkeɪ/ 这个名字:Spark 的默认存储格式、数据湖的标准文件格式、ClickHouse 和 DuckDB 的数据导入导出格式。但 Parquet 到底是什么?为什么它无处不在?
为了大家更好地阅读,我分成了几篇文章,我相信阅读它们会非常轻松,因为 Parquet 解决的都是一些非常实际的问题,大家很容易共鸣它在设计上的各种 trade-off。
Parquet 是什么,为什么要学习它
Apache Parquet 是一种列式存储的文件格式,它是 Apache 基金会的顶级项目。简单说,它是一种存数据的方式,就像 CSV、JSON 一样,把它理解为另一种文件格式就行了,但它把数据按列组织,而不是按行。
这个看似简单的改变,带来了巨大的性能提升——在分析查询场景下,Parquet 可以比 CSV 快 10-100 倍,同时文件体积小 5-10 倍。
你可能没有直接使用过 Parquet,但你用的很多工具很可能在底层都依赖它:
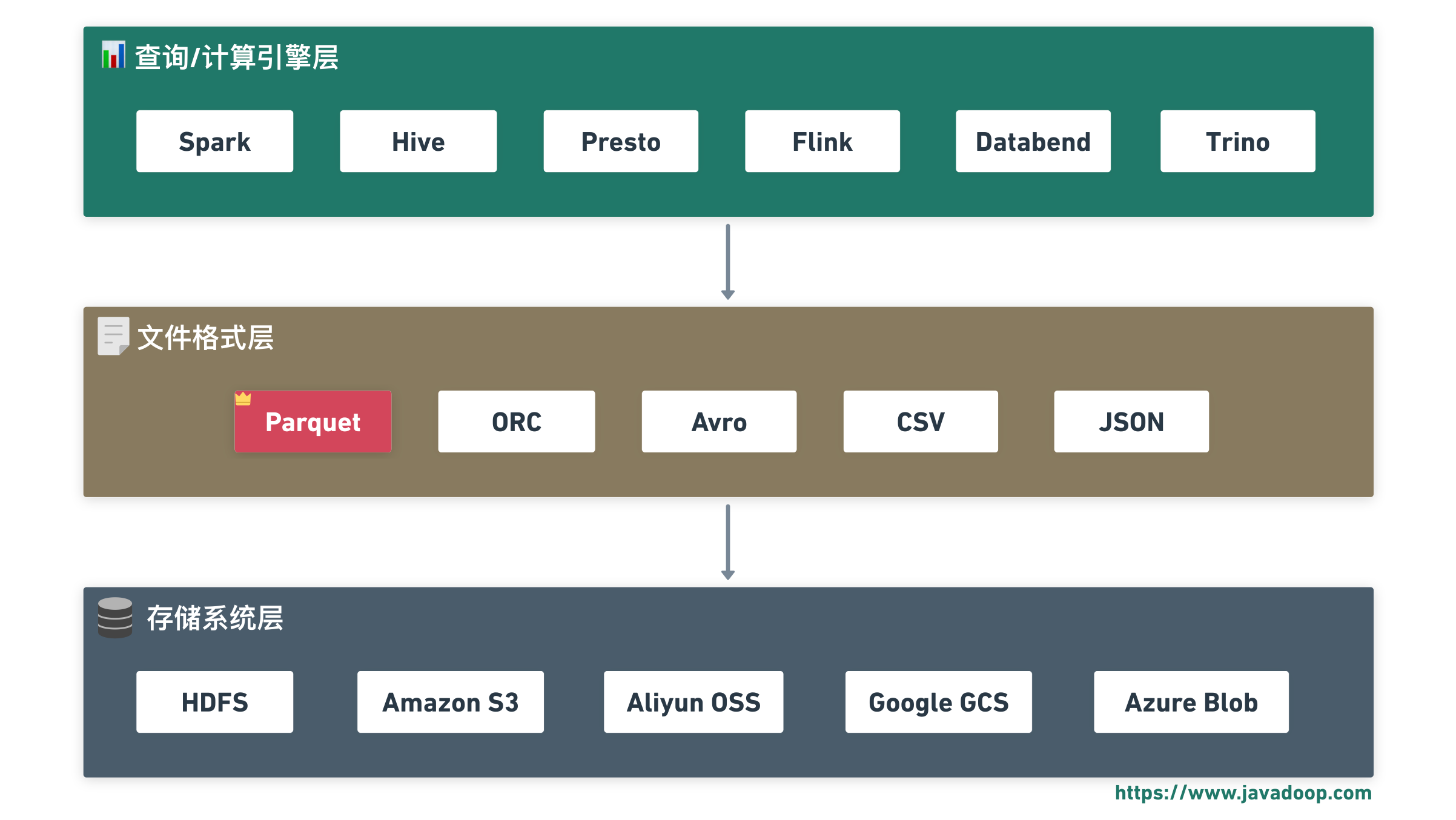
Databend、ClickHouse、DuckDB、Polars、Apache Arrow……这些现代数据系统,要么直接用 Parquet 作为存储格式,要么支持 Parquet 作为数据交换格式。理解 Parquet,就是理解这些系统的共同基础。
另外,列式存储是现代数据分析的核心技术。与其抽象地学习"列式存储"这个概念,不如通过一个具体的、被广泛使用的实现来学习,Parquet 就是一个非常好的素材。
Parquet 的设计非常精妙:
- 文件结构:Row Group、Column Chunk、Page 的层次设计
- 编码技术:字典编码、RLE、Delta 编码、Bit-Packing
- 嵌套结构处理:Repetition Level 和 Definition Level(来自 Google Dremel 论文)
这些不只是 Parquet 的知识,而是列式存储的通用知识。学会了这些,再去看 ORC、Arrow、ClickHouse 的存储设计,都会觉得似曾相识。
这个系列讲什么
这个系列一共 4 篇文章,帮你建立对 Parquet 的系统认识,能深入了解它的核心原理。
第 1 篇:理解列式存储:行式 vs 列式存储的对比,告诉你为什么列式存储适合分析场景。
第 2 篇:文件结构剖析:Row Group、Column Chunk、Page,告诉你 Parquet 文件内部长什么样。
第 3 篇:编码技术:Dictionary、RLE、Delta、Bit-Packing 等,学习 Parquet 是如何用各种技巧压缩数据的。
第 4 篇:Schema 与嵌套结构:Repetition Level、Definition Level,学习 Parquet 如何把嵌套数据"拍平"成列。
这 4 篇涵盖了 Parquet 最核心的设计思想,也是列式存储的通用知识。即使你不做大数据开发,理解这些也会让你对数据存储有更深的认识。
关于 Parquet 还有很多内容可以介绍,比如它在大数据生态中的实际使用,使用 Java、Rust 或者其他语言怎么读写一个 Parquet 文件,怎么设置各个参数以达到最好的性能等等。但是考虑到大部分读者可能不需要接触这些,所以就不再继续往后写了。AI 时代,大家很容易获取这些信息,我就是想带大家入个门,了解一些基础的内容,所以停在这里应该是一个不错的选择。
如果你准备好了,让我们从第一篇开始:理解列式存储。我们会从一个简单的问题出发——为什么同样的数据,换一种存储方式,查询速度能差 10 倍以上?
0 条评论