阅读本文的前提是你分别知道 Grafana 和 Prometheus 是什么,要有一些最基本的了解。
本文会用一些比较接近实际情况的例子来帮助初学者理解 Prometheus 的数据类型,读完本文,你应该能充分了解 Prometheus 中主要数据类型的工作原理,以及能根据自己的需要使用合适的函数配置出相应的 Grafana 图表。
如果你没有环境进行实操,建议自己用 docker 搞一下,花点时间准备环境还是值得投入的。所以为了写本文,我提前写了一篇非常简单的文章,介绍如何搭建环境,大家可以参考。
数据上报
Prometheus 和一般的 APM 工具不一样,它采用的是由 server 端主动 pull 的交互模型,就是你准备好本地数据,然后在 Prometheus server 上配置好数据所在的地址,接下来就是等 Prometheus 来主动、定期拉取数据。
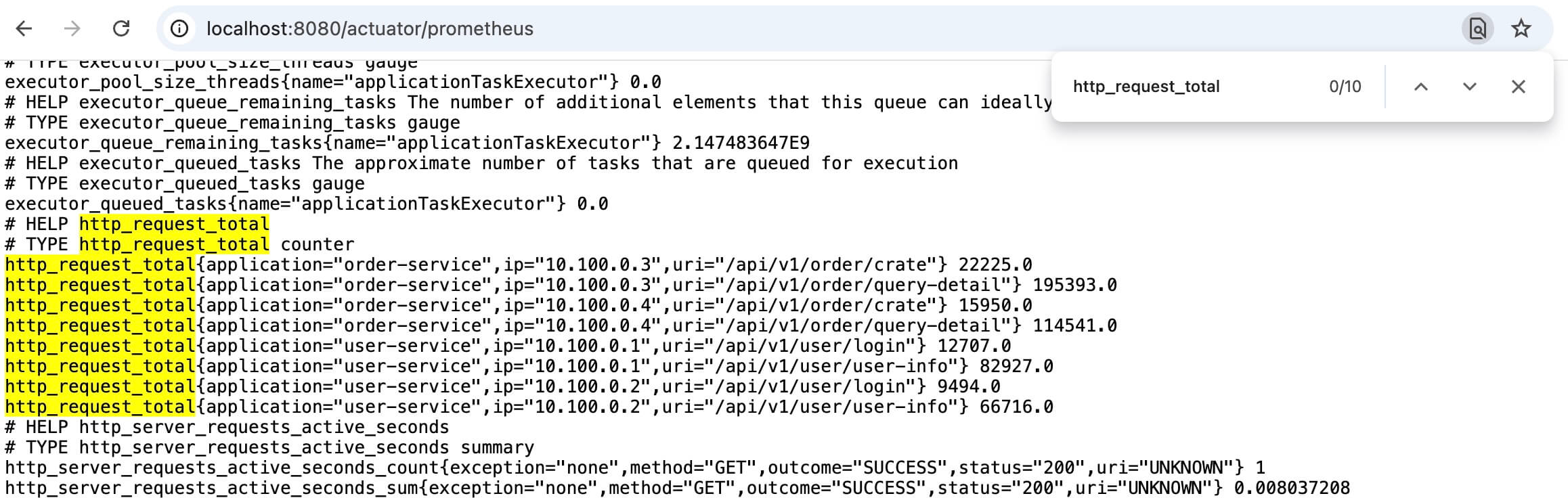
想要看到本地数据非常容易,对于 Spring Boot 应用来说,通常是访问 /actuator/prometheus 就可以了,当然不同的配置可能导致不同的地址,这里就不详述了。接口数据是纯文本的,采用 OpenMetrics 标准来组织内容。
内容类似如下:
# HELP executor_queued_tasks The approximate number of tasks that are queued for execution
# TYPE executor_queued_tasks gauge
executor_queued_tasks{name="applicationTaskExecutor"} 0.0
# HELP http_request_total
# TYPE http_request_total counter
http_request_total{application="order-service",ip="10.100.0.3",uri="/api/v1/order/crate"} 2494624.0
http_request_total{application="order-service",ip="10.100.0.3",uri="/api/v1/order/query-detail"} 2.1704952E7# 开头的行主要描述这个指标是干啥的,以及定义它的数据类型,然后紧跟着时间序列以及它们当前的值。
这个 OpenMetrics 标准最早就是 Prometheus 的内部数据格式规范,但是后来想把这个数据标准推广出来,让其他的 apm 工具可以直接使用,所以成立了一个项目单独发展,但是最新消息是,OpenMetrics 又合并回了 Prometheus 项目。
Prometheus 有好几种数据类型,但是通常我们只需要关注 counter、gauge、histogram、summary 这 4 种,对于初学者来说,counter 和 gauge 是比较容易理解的,可以先充分了解这两个类型以后再扩展到其他类型。
在 Java 中,我们最常用到的客户端库是 MicroMeter,结合 spring boot actuator,能非常简单地进行打点。
基本概念解释
理解 Prometheus 最好的方式是,可能是自己先想一想要实现类似的需求,你会怎么做?你需要怎么组织数据?
本章对 Prometheus 的数据做一个抽象化的解释,这样可以帮助读者更容易理解后面的内容。
Prometheus 的核心是一个时序数据库,它按照时间序列来存储数据,所以要先理解一个时间序列意味着什么。
举个例子,我们要统计每个接口被访问的次数,那么可能会形成下面几条数据:
http_request_total{uri="/api/placeOrder",method="POST",application="xxx-dog",instance_ip="10.110.0.1",} 10
http_request_total{uri="/api/placeOrder",method="POST",application="xxx-dog",instance_ip="10.110.0.2",} 8
http_request_total{uri="/api/queryOrder",method="GET",application="xxx-dog",instance_ip="10.110.0.1",} 25在这个示例数据中,其中 /api/placeOrder 接口,在 10.110.0.1 实例上被访问了 10 次,在 10.110.0.2 实例上被访问了 8 次;而 /api/queryOrder 接口在 10.110.0.1 实例上被访问了 25 次。
我们的每条数据包含了:
- 指标名称 metric name:http_request_total
- 标签 labels:uri, method, application, instance_ip 以及它们的值
- 样本值:比如上面这个是 counter 类型的指标,它的值是不断累加上去的,那这个样本值就代表当前实例从启动开始累积到现在的某接口的请求次数
- 隐式包含了时间戳 timestamp,因为数据是一直在变化的,当前数据仅代表当前时间的值
我们把一个时间序列的存储看成 kv 存储,那么 key 就是 指标名称和标签键值对,它们定义了一个唯一的时间序列,而 value 则由时间戳和值组成。
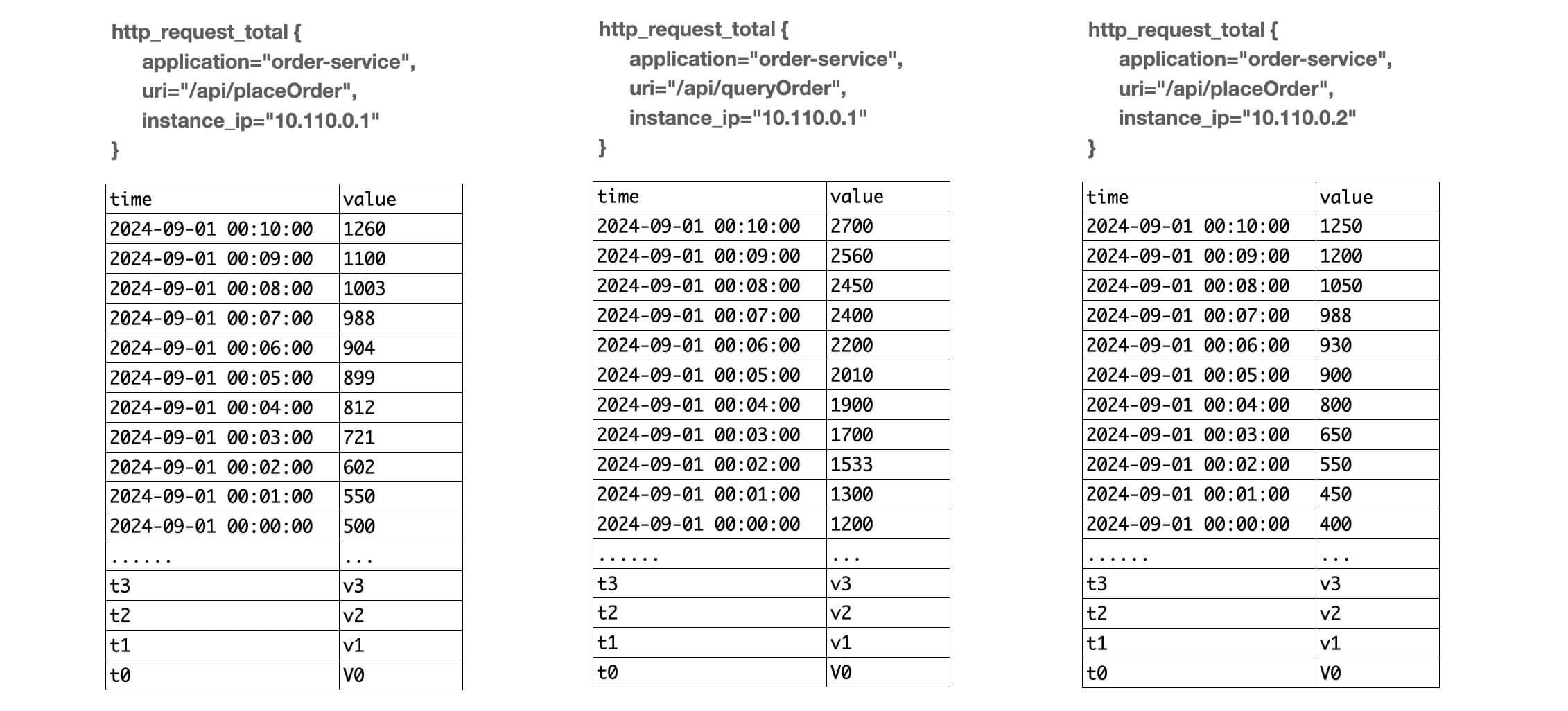
由于每个时间序列都需要单独储存时序数据,所以我们需要注意时间序列不能太多,对于某个指标名来说,标签键值对的不同组合就决定了时间序列的数量。
最终,在 Prometheus 多次拉取数据以后,会得到类似下面的 key-value 数据:
key:
http_request_total{uri="/api/placeOrder",method="POST",application="xxx-dog",instance_ip="10.110.0.1"}
value:
[
{time: 2024-07-30 00:00:00, value: 10},
{time: 2024-07-30 00:00:05, value: 15},
{time: 2024-07-30 00:00:10, value: 20},
{time: 2024-07-30 00:00:15, value: 33},
]这里面 key 就是一个时间序列,然后 value 对应这个时间序列在每个时间点的值,后面要介绍的很多函数,无非就是取某些时间段的值出来做各种运算。
当然,这是抽象化以后的解释,感兴趣的同学可以去研究一下它的 TSDB 设计。
另外,通常我们不允许同一个指标,使用不同的 label names 组合,比如:
http_request_total{uri="xx",method="xx"}
http_request_total{uri="xx",application="xx"}第一个使用了 uri+method,第二个使用了 uri+application,可以参考这个 issue(https://github.com/micrometer-metrics/micrometer/issues/877)
Counter 类型
Counter 就是一个计数器,它的值是一直往上增加的(不重启的情况下)。
首先我们先来一个例子,下面是测试代码:

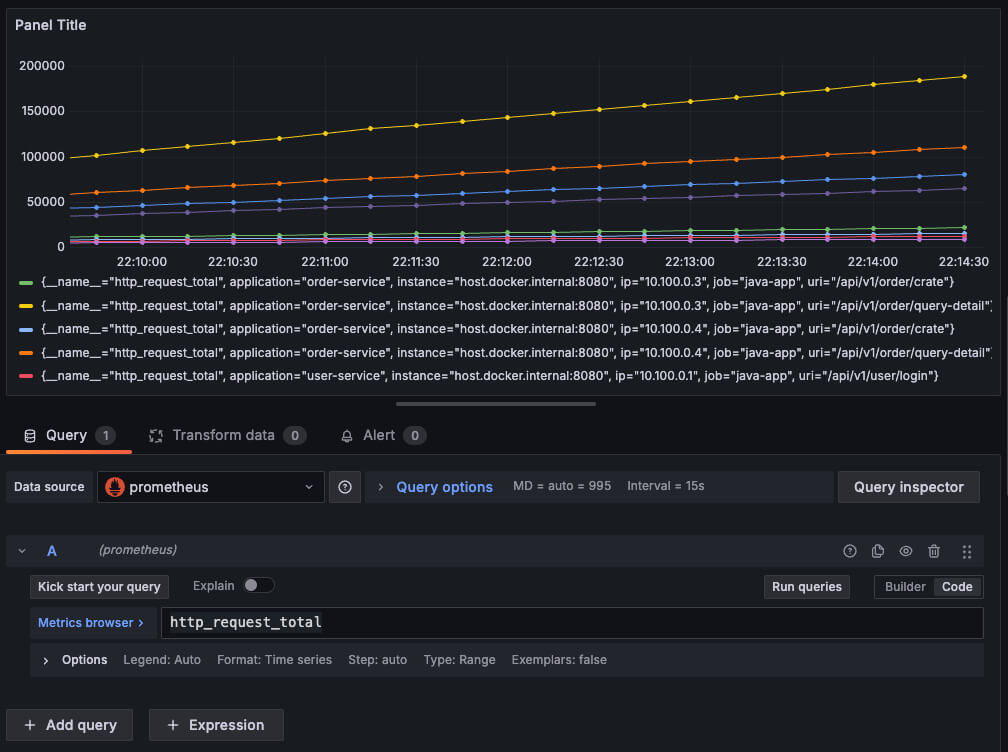
在这里例子中,有 2 个应用 order-service 和 user-service,然后每个应用分别有 2 个实例,并且每个应用有 2 个接口,共 8 个时间序列。每次来一个请求,对相应的时间序列增加随机的数值。
user-service:
ip list: 10.100.0.1, 10.100.0.2
api list: /api/v1/user/login, /api/v1/user/login
order-service:
ip list: 10.100.0.3, 10.100.0.4
api list: /api/v1/order/crate, /api/v1/order/query-detail我们让它跑起来,每秒钟执行一次,然后我们一直刷新 /actuator/prometheus,可以看到这8个时间序列后面的数值一直在增长。
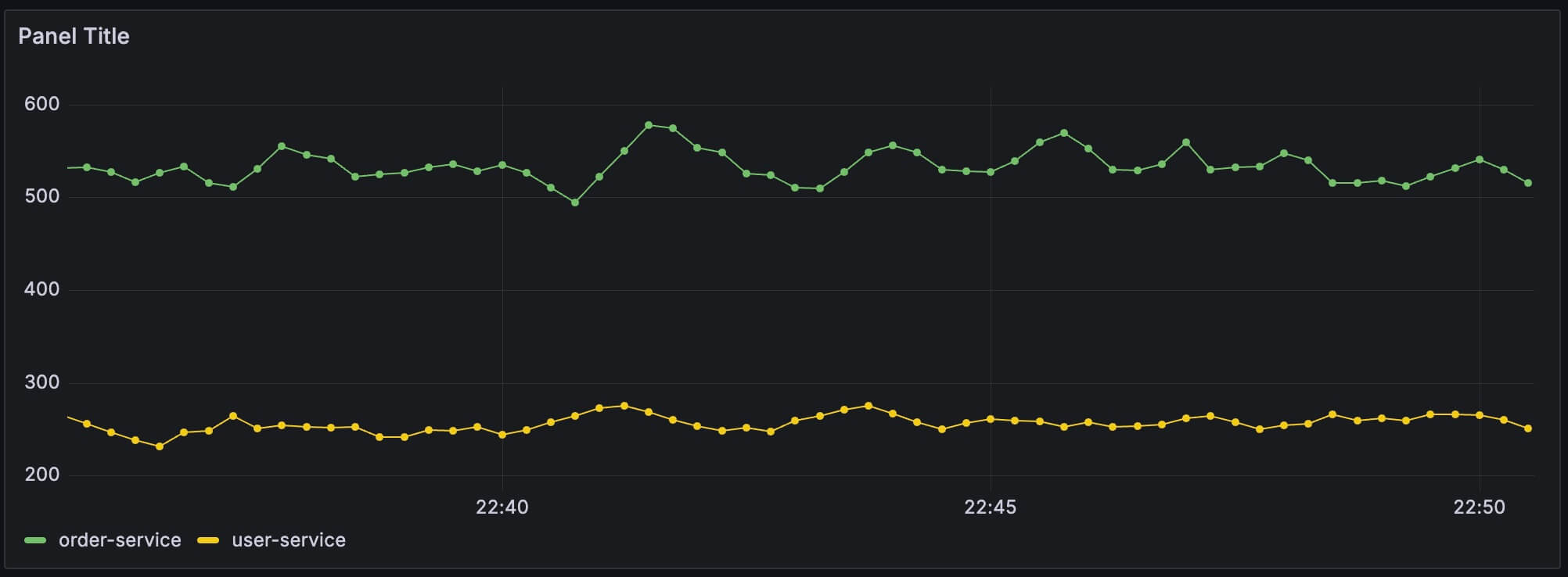
我们在 Grafana 中展示它们,可以看到每个时间序列的值一直在增加,是一条条单调增加的折线:
单单看这个一直增长的图通常没什么意义,能用的场景太少了,所以我们要先来了解下面的几个函数
- rate: 计算每秒平均增长率
- increase: 计算总增长量
- irate: 计算瞬时增长率
rate 函数制图
rate 函数的含义是每秒的平均增长率,其实就类似 QPS 的意思。
比如我随便取其中一个时间序列出来:{__name__="http_request_total", application="order-service", instance="host.docker.internal:8080", ip="10.100.0.3", job="java-app", uri="/api/v1/order/crate"}
使用 table 展示出来原始的值:
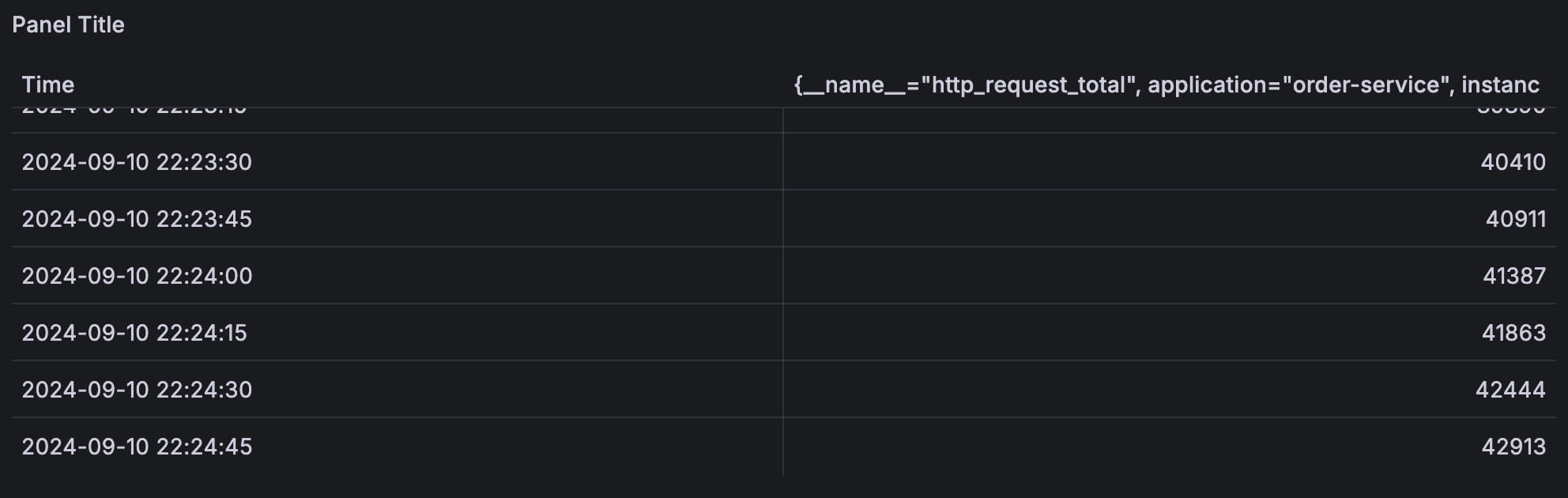
从上图中可以看到,这个时间序列每15秒被采集一次,样本值一直在增长。
下面这个图,能帮助你非常容易理解 rate 做出来的折线图代表什么含义:
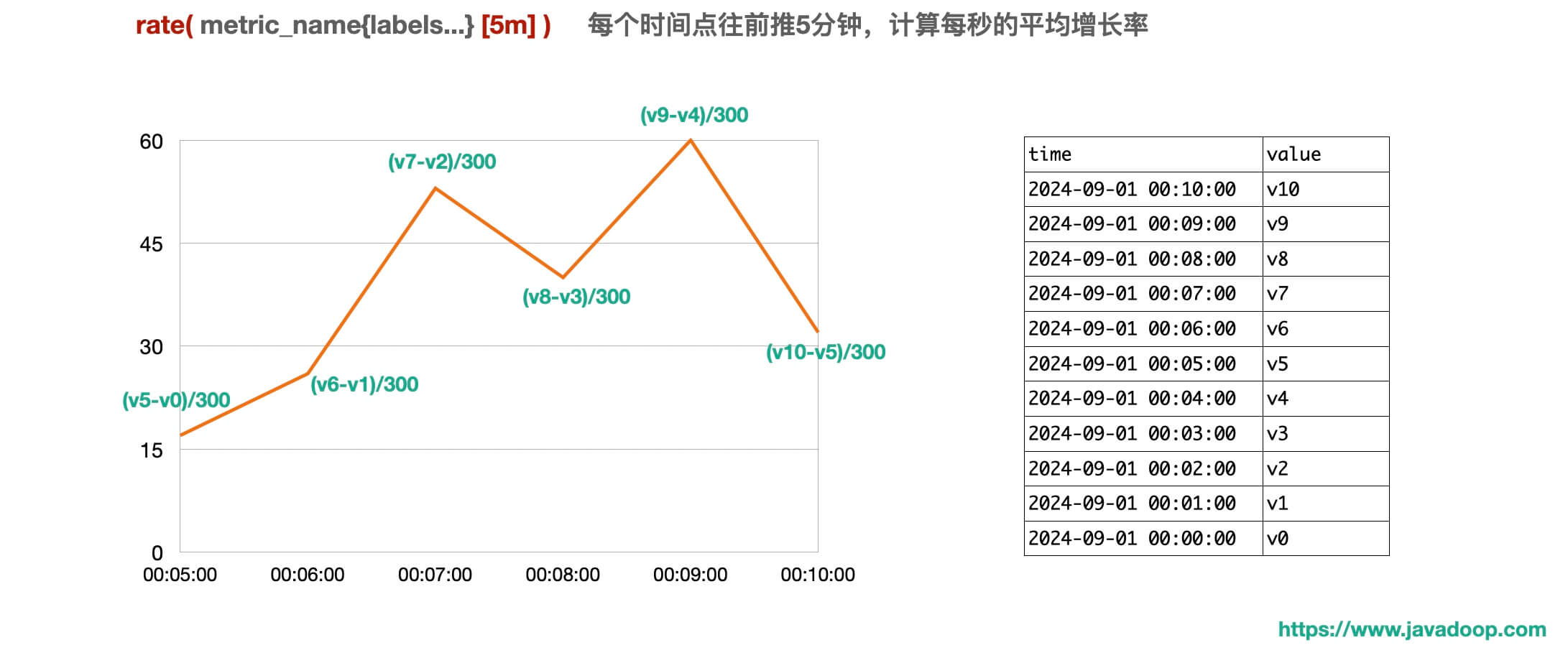
所有的折线图是由一个个点连接起来的,我们需要关注每个点的数值是怎么计算出来的。
速率=数量/时间,所以我们在做图的时候,还需要考虑分母的时间取多长比较合适,比如下面我先使用 1 分钟作为一个统计区间,也就是说 图上每个时间点的数值 = 这个时间点往前1分钟的数据增长量 / 60秒。
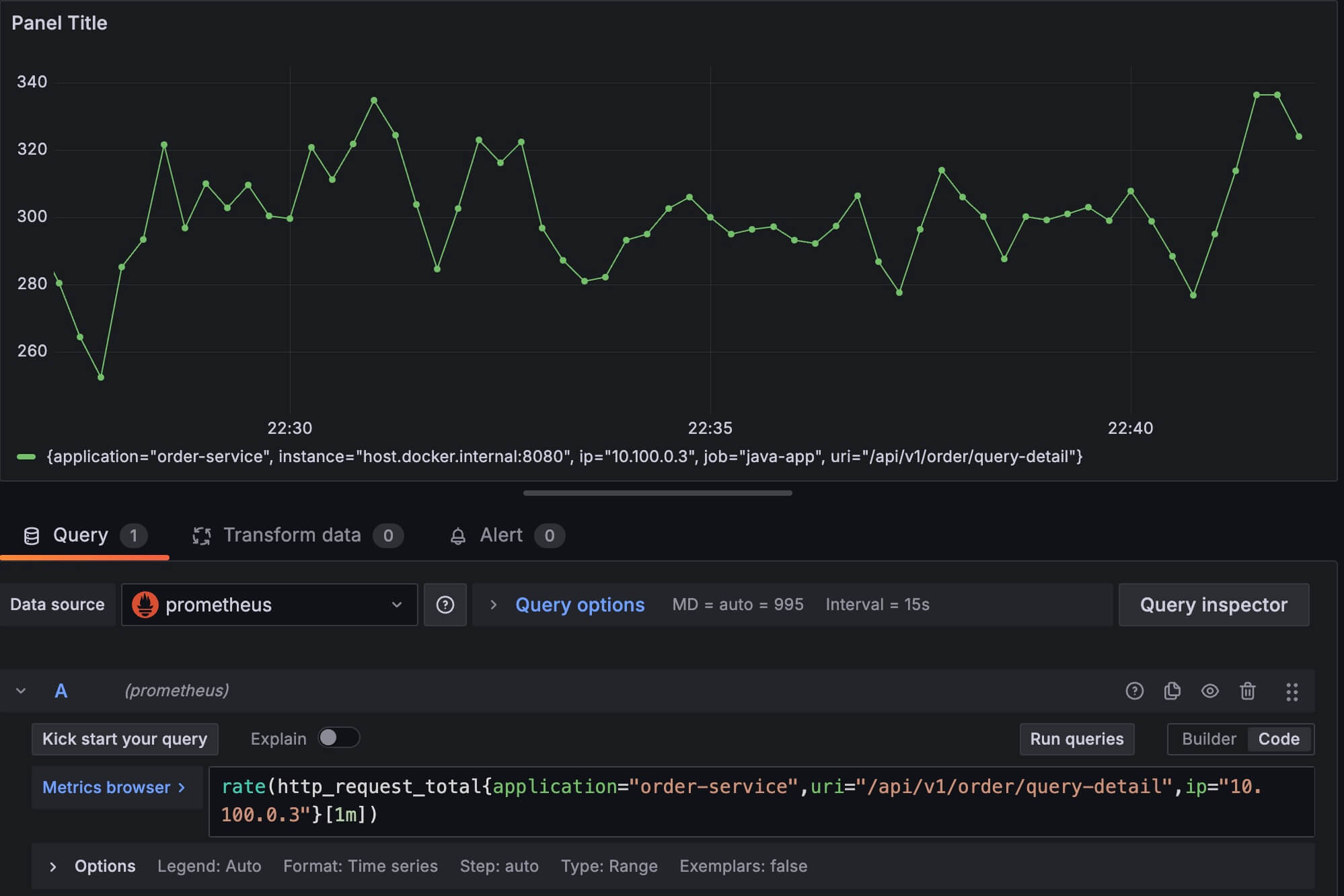
如果我使用 5 分钟作为一个统计区间,并且把它们放在一起对比:
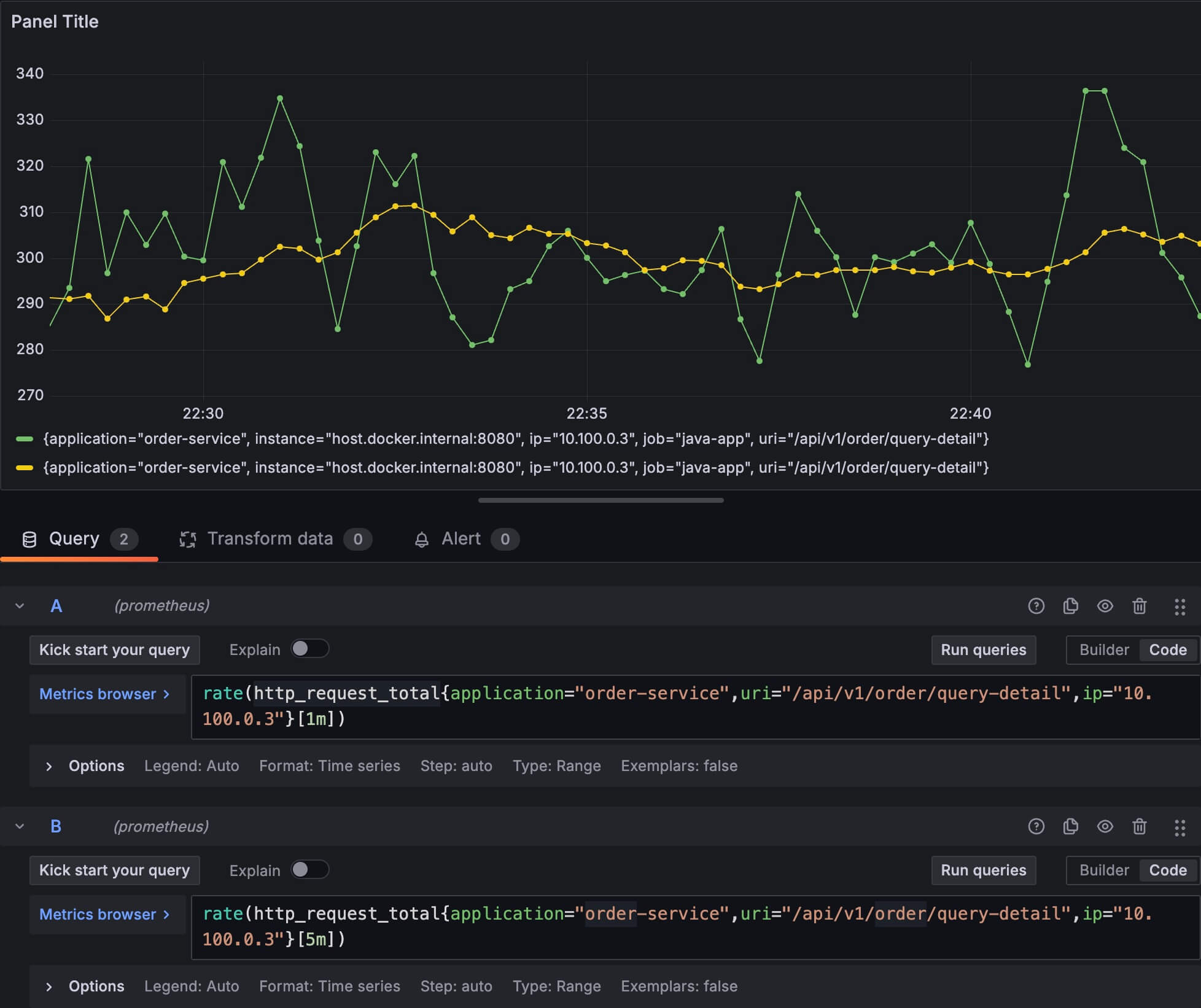
可以看到用 5 分钟作为一个统计区间,画出来的图比较平滑,这个稍微想一下就很容易理解为什么了,因为图上每 2 个相邻的点,他们的时间区间几乎都是重叠的。根据公式 速率=数量/时间,分母相同,分子数量差异不大,所以就表现得比较平滑。
如果只用 rate 函数,那么所有被搜索到的指标都会被展示出来,比如下面这个,它显示了 8 个时间序列:
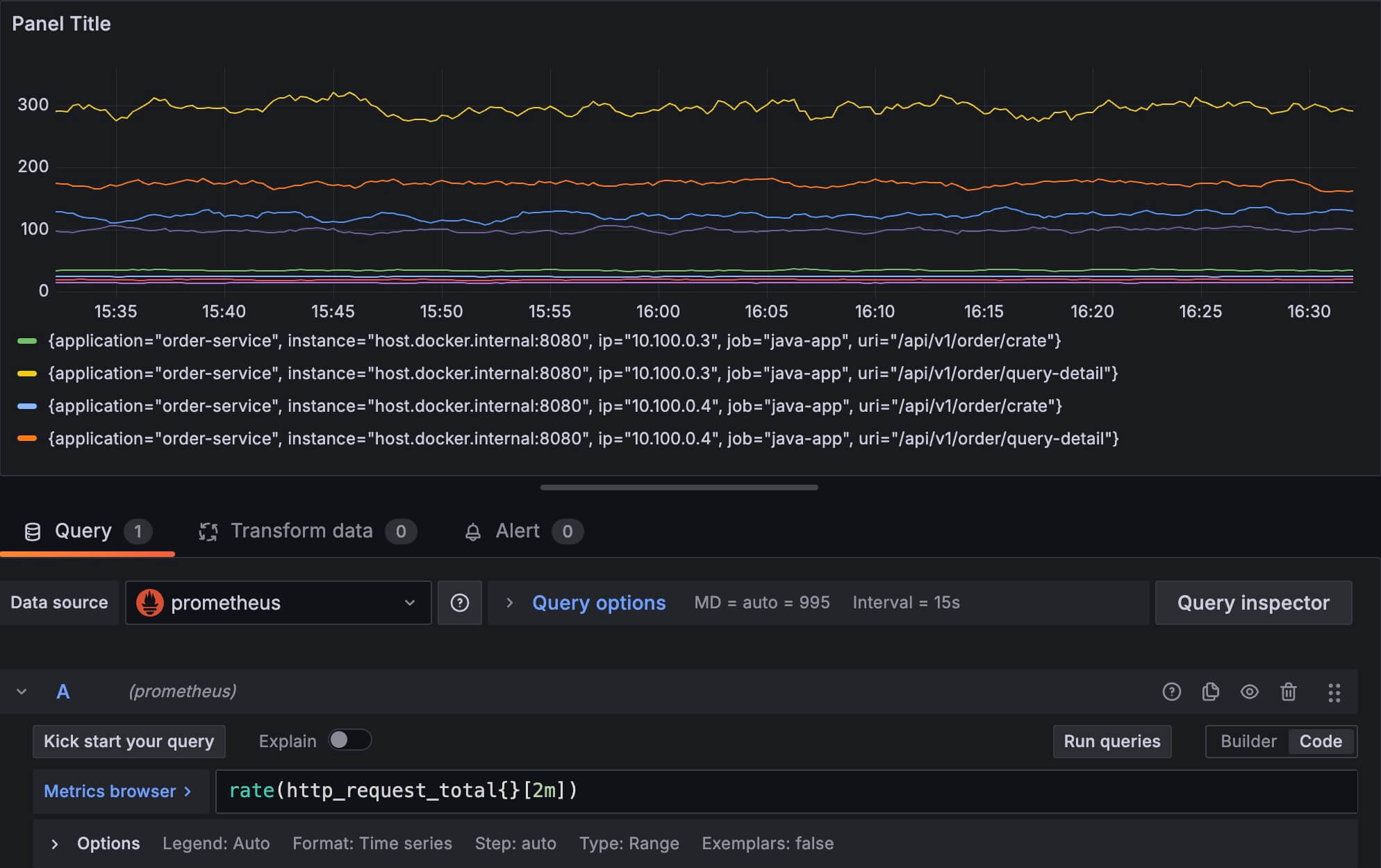
所以我们通常需要对结果进行聚合,这里需要用到 sum 函数,它非常简单,就是把搜索到的满足条件的时间序列求和。

比如我们可以按照 application 的维度,或者按照 application+ip+接口 的维度,如下:
sum( rate(http_request_total[1m]) ) by(application),这样我们可以看到每个应用的总体 QPS 了,而不是某个接口的 QPS:
sum( rate(http_request_total[1m]) ) by(application, uri),这样我们可以看到每个接口的 QPS:
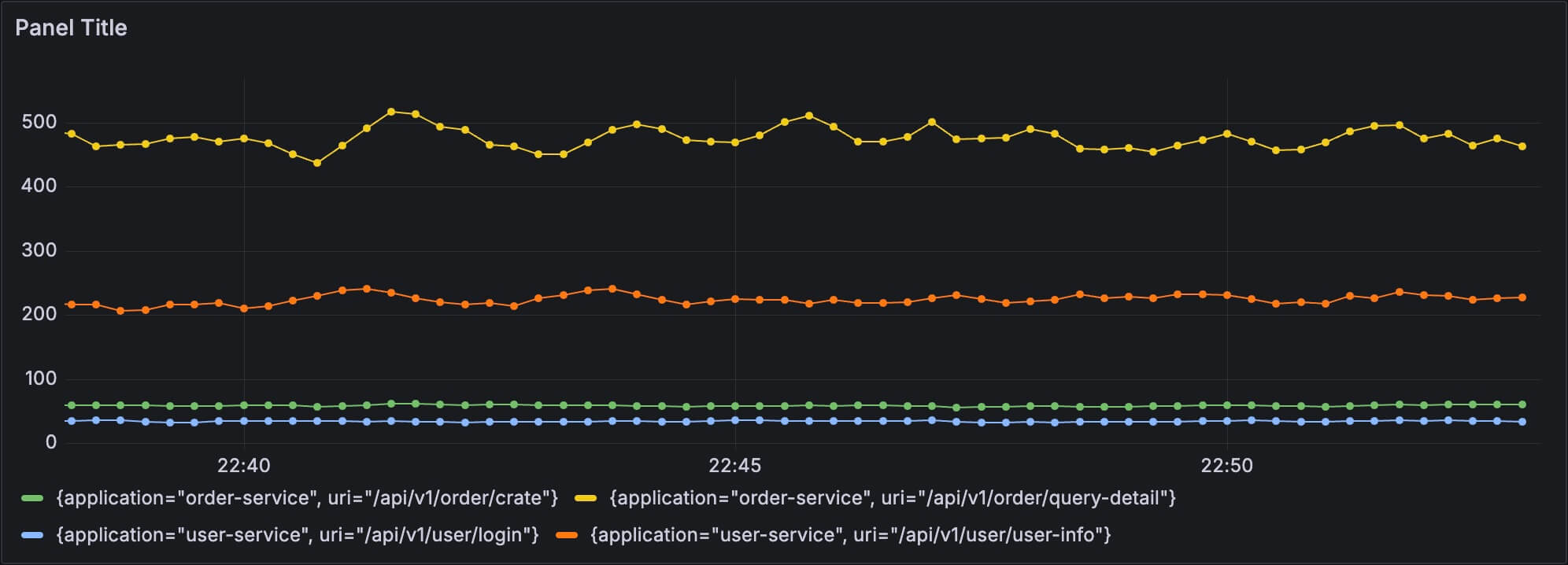
sum by 有两种写法,把 by 写在前面也是可以的,比如 sum by(application, uri) (rate(http_request_total[1m]))
sum 函数还有一个特点,就是它的结果是分组数据,在一些场景中很适合用来做对比,也就是饼状图:

这个示例里面,可以看到流量分配是不均匀的,order-service 有两个实例,但是有一个实例明显有较多的流量。
总结一下 rate 函数,它很适合用来制作代表速率的图,比如订单的创建速率、网络的速率、接口的 QPS 等等,同时它适合搭配 sum 函数一起使用。
irate 函数制图
有了 rate 函数的概念以后,理解 irate 就会容易很多。
比如某个指标,每 10 秒被采集一次数据,有如下数据:
2024-09-09 00:00:00 100
2024-09-09 00:00:10 150
2024-09-09 00:00:20 160
2024-09-09 00:00:30 400
2024-09-09 00:00:40 450
2024-09-09 00:00:50 600
2024-09-09 00:01:00 1000先观察一下上面这组数据,每 10 秒增加的数量非常不均匀,有些时候只增加了 10 个,但是最后 10 秒一下子增加了 400 个。
如果我们使用 rate 函数,每分钟作为一个统计区间,计算在 00:01:00 这个时间点的速率,得到的结果是 (1000-100)/60=15。
但是如果我们使用 irate 函数,它只会考虑最后两个数据点的增长率,也就是说,在 00:01:00 这个时间点的瞬时增长率,为 (1000-600)/10=40。
从这个例子,我们可以看到,虽然 rate 和 irate 都是描述增长率,但是 irate 对数据的增长速率非常敏感,而 rate 表现得比较平滑。
同样的,下面这张图能帮助你非常容易理解 irate 函数的图表:

下面,我把其中的一个时间序列分别用 rate 函数和 irate 画一条折线出来,可以对比着看一下它们表现出来的信息:
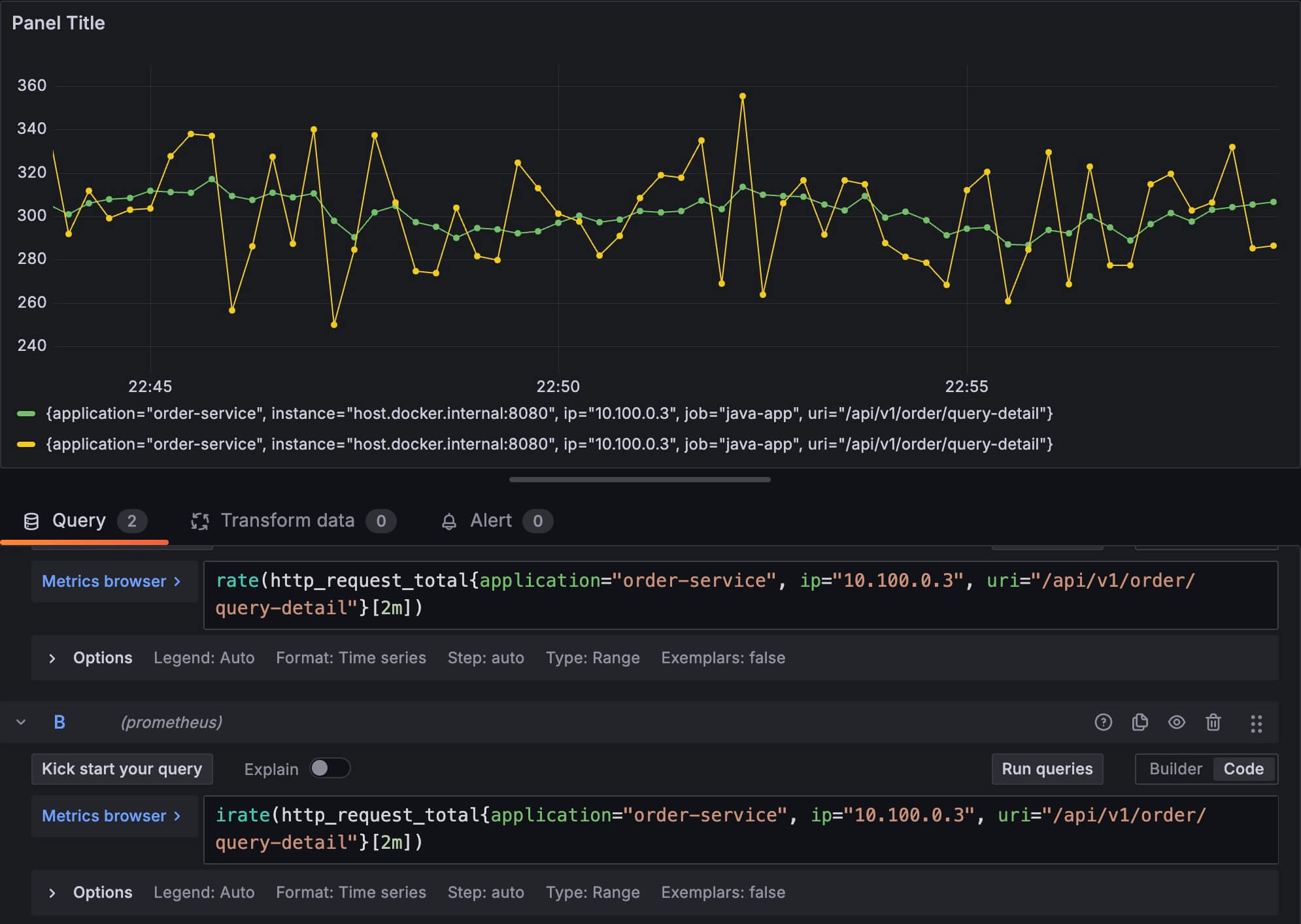
黄色的线是 irate 函数画出来的,显然它的波动比较大,对数据的变化比较敏感。
既然 irate 只取最后的两个数据,所以我们其实也可以猜到,下面的两个表达式,虽然时间范围看上去差异很大,一个 1m 一个 10m,但是基本上可以肯定,做出来的图是一样的,之所以要指定时间,是因为怕采样频率的问题,以及数据可能有丢失等。
irate(http_request_total{application="order-service", ip="10.100.0.3", uri="/api/v1/order/query-detail"}[1m])
irate(http_request_total{application="order-service", ip="10.100.0.3", uri="/api/v1/order/query-detail"}[10m])increase 函数制图
increase 非常容易理解,它代表在一段时间内,第一个数据到最后一个数据,它们之间的差值。
比如我设置一个这种图:
increase(http_request_total{application="order-service", ip="10.100.0.3", uri="/api/v1/order/query-detail"}[5m])图上出现的每个点,它代表这个时间点往前5分钟,这个时间序列总共增长了多少数值。
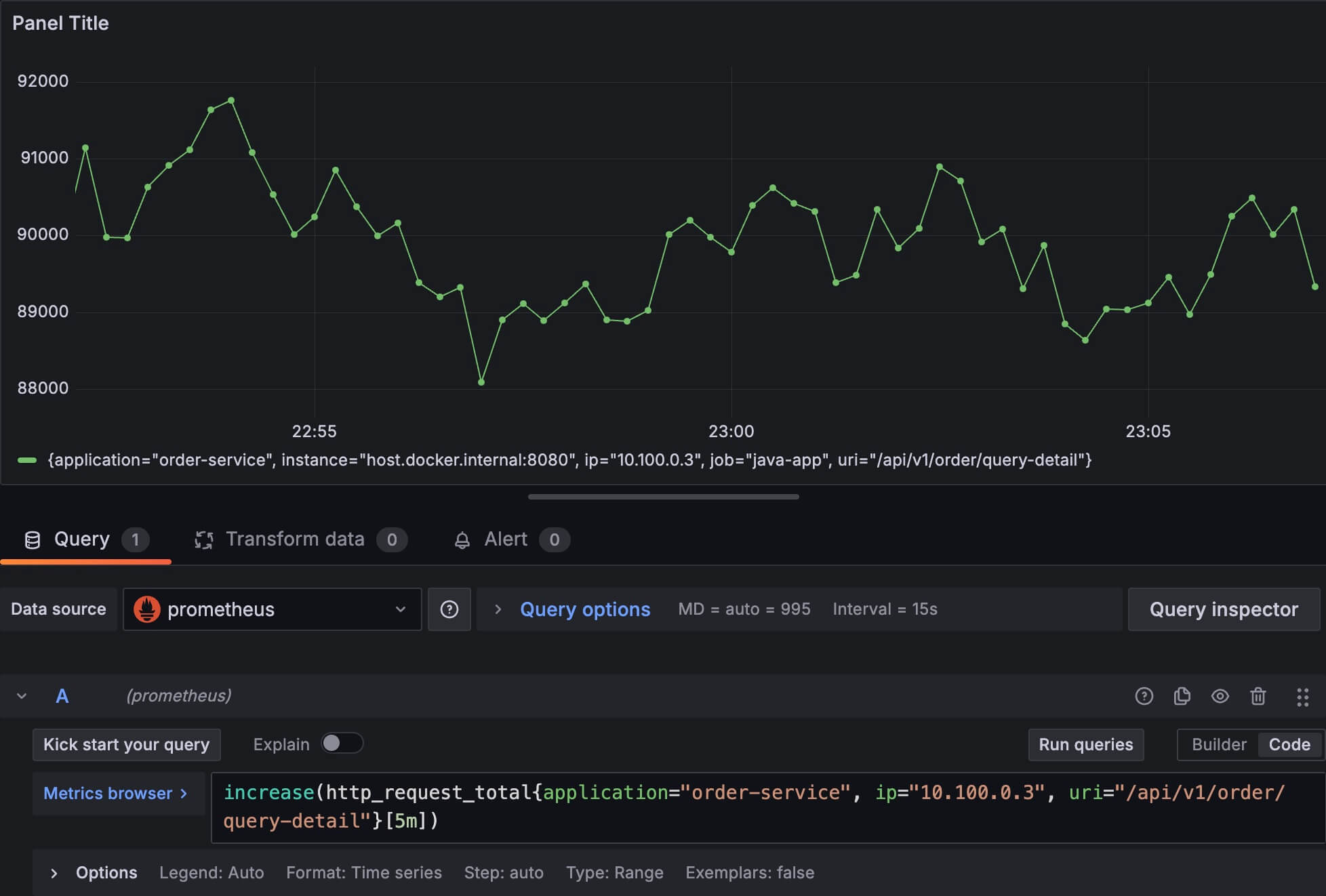
其实大家应该很容易发现,increase 和 rate 函数用了一样的数据,都是一个时间区间的第一条和最后一条数据。
所以从数学上,很容易推出:increase(v[t]) = rate(v[t]) * t。因此,理论上我们是可以只使用它们之中的一个函数的。
很多时候,我们想知道一段时间的总体变化,而不是变化速率,这个时候我们一般会使用 increase 函数。比如我想知道过去 24 小时内的新用户注册数、24 小时订单数等,这种图可以不局限于做折线图或者是柱状图,也可以做饼图。
counter 类型大概就说这么多,最后需要指出的是,前面我们说过了 counter 的数据是一直增长的,但是如果我们的应用重启了,也就是说,本地的数据发生了重置,Prometheus 会记录新的从 0 开始的样本值,但是对 rate, irate, increase 这些函数,会特殊处理,看下面这两个图就清楚了。
首先我们不使用任何函数,先把原始数据展示出来:
http_request_total{application="order-service", ip="10.100.0.3", uri="/api/v1/order/query-detail"}
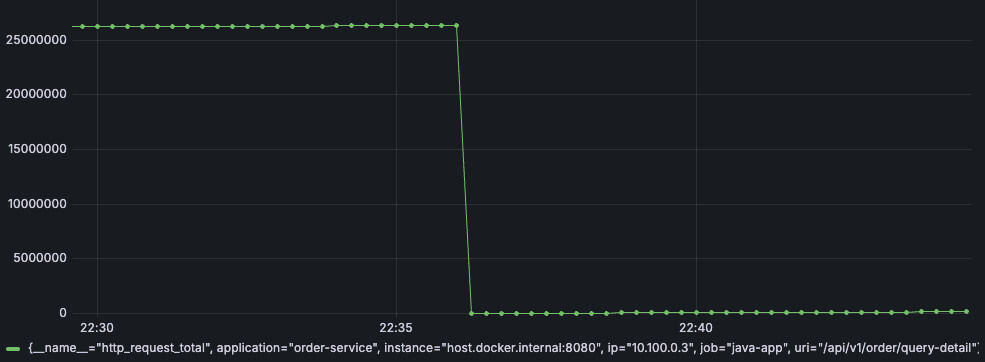
从上图可以看到,这个时间序列是发生过 reset 的,下面我们用 rate 函数画图:
rate(http_request_total{application="order-service", ip="10.100.0.3", uri="/api/v1/order/query-detail"}[2m])
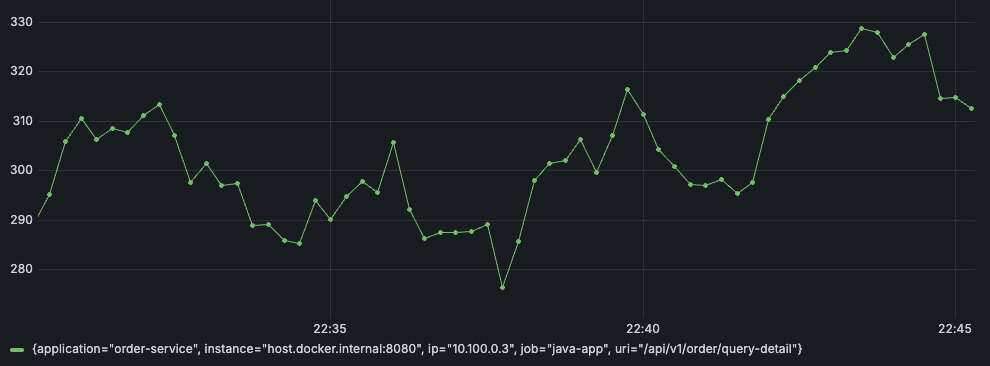
可以看到,rate 函数自动处理了 reset 的情况。
Gauge 类型
Gauge 类型非常简单,它就是代表某个指标在某个时间点的数值,基本上每个点的数值都是独立的,前后之前没什么关联。
它的使用场景也非常多,比如当前的 CPU 使用率、内存使用率、kafka 的 consumer lag、当前线程数等等。
比如下面是我的 cpu 使用率的几次采样数据:
2024-09-11 22:14:45 0.212
2024-09-11 22:15:00 0.165
2024-09-11 22:15:15 0.189
2024-09-11 22:15:30 0.257
2024-09-11 22:15:45 0.207接下来,我们考虑 gauge 数据通常的呈现方式。
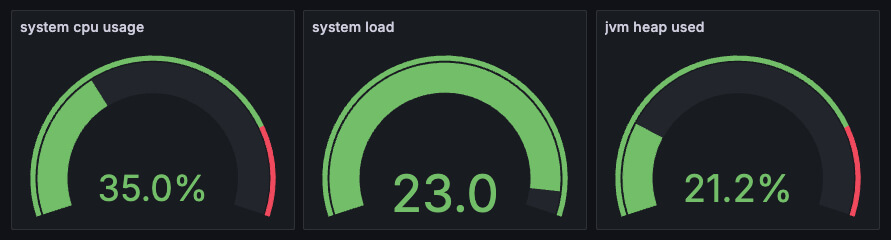
首先是,它非常适合用来做一些仪表盘的图,比如下面这种状态图,我们想看到现在的系统的实时信息:
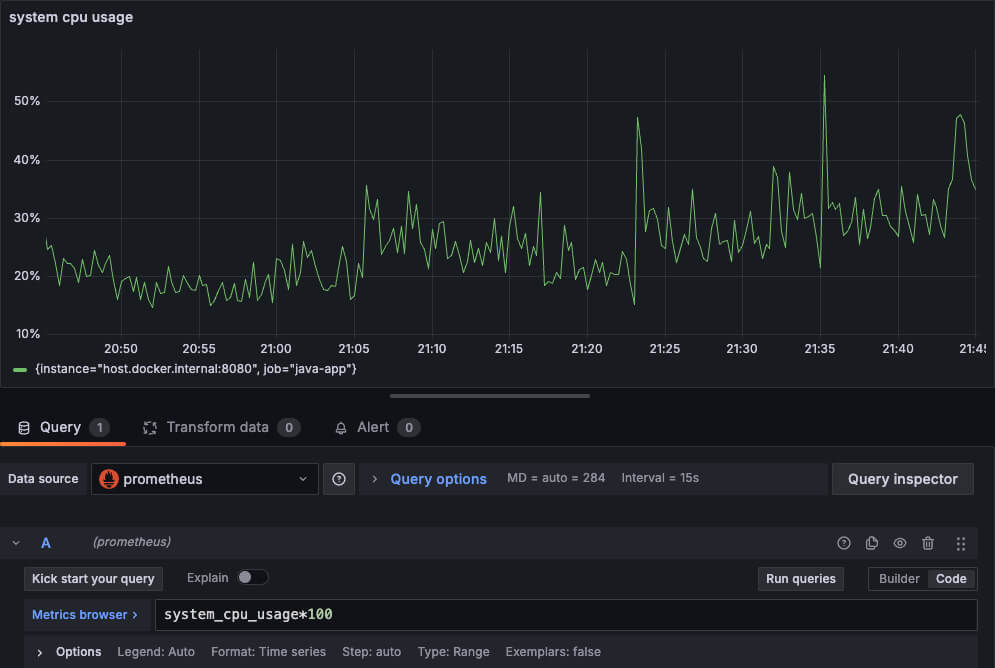
当然,把它们做成折线图也很有用,可以看到数据的变化趋势,比如下面这个 cpu 使用率的趋势图:
另一个很好用的图,是 stat panel,也就是把上面两个结合在一起,既可以看到趋势,也可以看到当前最新值。
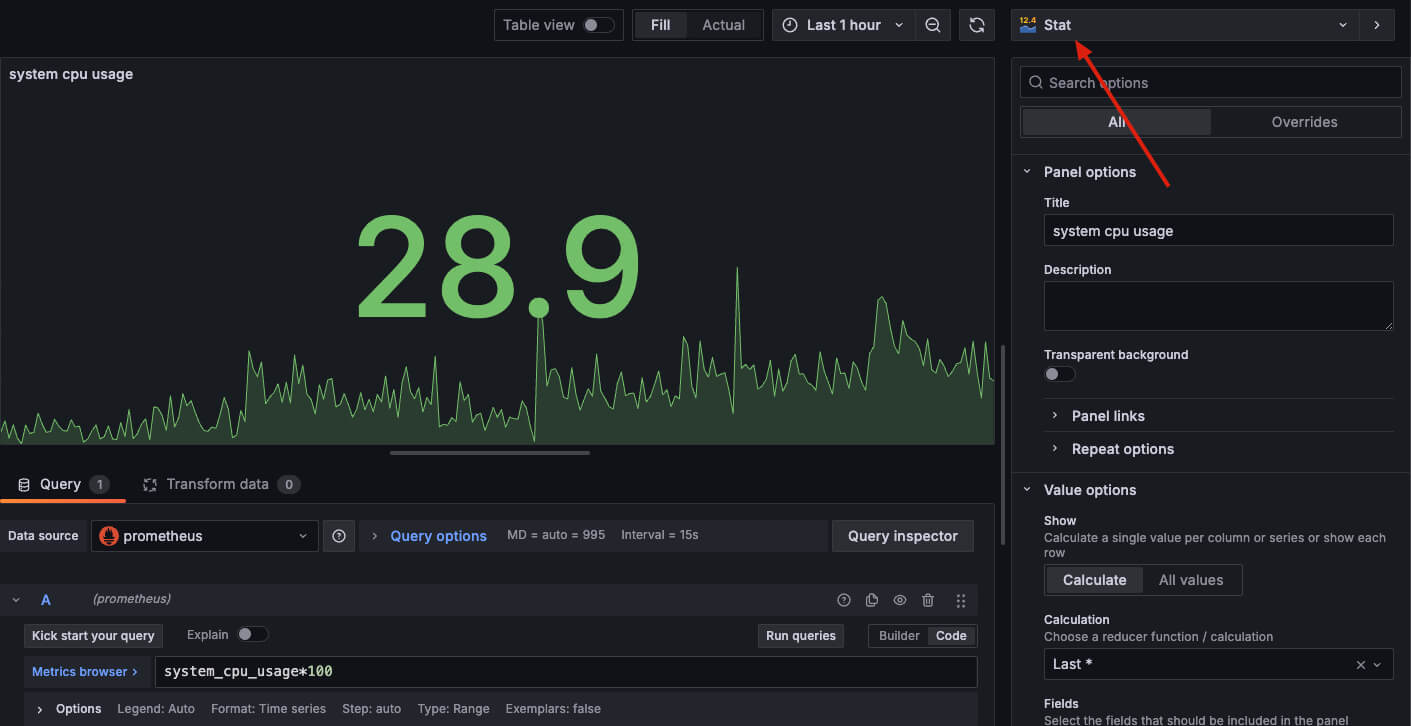
这里要强调一下,如果你觉得有需要,你依然可以使用前面介绍的 rate、irate、increase 等这些函数在 gauge 类型上,虽然很奇怪。对这些函数而言,gauge 和 counter 都是一样的时序数据,只不过 counter 类型的数据有可能要处理数据重置的情况,而 gauge 不存在。
Summary 类型
接下来我们要进入到 Summary 类型的介绍,它比 counter 和 gauge 稍微复杂一些,我们要介绍一些内部细节,才能帮助大家理解它,进而更容易理解后面要介绍的 Histogram 类型。
首先,我们需要在 application.properties 文件中配置下面这 3 个属性(当然你也可以通过 @Configuration 来配置),这里指明我们要统计 http.request 的 P90 和 P99,另外指定了使用 3 个时间窗口,每个窗口是 1 分钟,后面会解释它们的作用。
management.metrics.distribution.percentiles.[http.request]=0.9, 0.99
management.metrics.distribution.buffer-length.[http.request]=3
management.metrics.distribution.expiry.[http.request]=1m它的 API 也非常简单,下面我模拟这些接口,每秒钟被请求一次,每次耗时几十到几百毫秒:

请注意这里我使用的 API,我调用了 Metrics#timer 方法,name 我使用的是 http.request,labels 还是和其他数据类型一致。
下面是从本地获取到的数据:
# HELP http_request_seconds
# TYPE http_request_seconds summary
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create",quantile="0.9"} 0.788529152
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create",quantile="0.99"} 0.788529152
http_request_seconds_count{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create"} 11
http_request_seconds_sum{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create"} 6.382
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/query-detail",quantile="0.9"} 0.074448896
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/query-detail",quantile="0.99"} 0.0786432
http_request_seconds_count{application="order-service",ip="10.100.0.3",uri="/api/v1/order/query-detail"} 11
http_request_seconds_sum{application="order-service",ip="10.100.0.3",uri="/api/v1/order/query-detail"} 0.619
http_request_seconds{application="order-service",ip="10.100.0.4",uri="/api/v1/order/create",quantile="0.9"} 0.956301312
http_request_seconds{application="order-service",ip="10.100.0.4",uri="/api/v1/order/create",quantile="0.99"} 0.956301312
http_request_seconds_count{application="order-service",ip="10.100.0.4",uri="/api/v1/order/create"} 11
http_request_seconds_sum{application="order-service",ip="10.100.0.4",uri="/api/v1/order/create"} 8.571
http_request_seconds{application="order-service",ip="10.100.0.4",uri="/api/v1/order/query-detail",quantile="0.9"} 0.038797312
http_request_seconds{application="order-service",ip="10.100.0.4",uri="/api/v1/order/query-detail",quantile="0.99"} 0.038797312
http_request_seconds_count{application="order-service",ip="10.100.0.4",uri="/api/v1/order/query-detail"} 11
http_request_seconds_sum{application="order-service",ip="10.100.0.4",uri="/api/v1/order/query-detail"} 0.333
http_request_seconds{application="user-service",ip="10.100.0.1",uri="/api/v1/user/login",quantile="0.9"} 0.281018368
http_request_seconds{application="user-service",ip="10.100.0.1",uri="/api/v1/user/login",quantile="0.99"} 0.297795584
http_request_seconds_count{application="user-service",ip="10.100.0.1",uri="/api/v1/user/login"} 11
http_request_seconds_sum{application="user-service",ip="10.100.0.1",uri="/api/v1/user/login"} 2.166
http_request_seconds{application="user-service",ip="10.100.0.1",uri="/api/v1/user/user-info",quantile="0.9"} 0.025690112
http_request_seconds{application="user-service",ip="10.100.0.1",uri="/api/v1/user/user-info",quantile="0.99"} 0.025690112
http_request_seconds_count{application="user-service",ip="10.100.0.1",uri="/api/v1/user/user-info"} 11
http_request_seconds_sum{application="user-service",ip="10.100.0.1",uri="/api/v1/user/user-info"} 0.211
http_request_seconds{application="user-service",ip="10.100.0.2",uri="/api/v1/user/login",quantile="0.9"} 0.360710144
http_request_seconds{application="user-service",ip="10.100.0.2",uri="/api/v1/user/login",quantile="0.99"} 0.37748736
http_request_seconds_count{application="user-service",ip="10.100.0.2",uri="/api/v1/user/login"} 11
http_request_seconds_sum{application="user-service",ip="10.100.0.2",uri="/api/v1/user/login"} 3.292
http_request_seconds{application="user-service",ip="10.100.0.2",uri="/api/v1/user/user-info",quantile="0.9"} 0.070254592
http_request_seconds{application="user-service",ip="10.100.0.2",uri="/api/v1/user/user-info",quantile="0.99"} 0.0786432
http_request_seconds_count{application="user-service",ip="10.100.0.2",uri="/api/v1/user/user-info"} 11
http_request_seconds_sum{application="user-service",ip="10.100.0.2",uri="/api/v1/user/user-info"} 0.552
# HELP http_request_seconds_max
# TYPE http_request_seconds_max gauge
http_request_seconds_max{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create"} 0.788
http_request_seconds_max{application="order-service",ip="10.100.0.3",uri="/api/v1/order/query-detail"} 0.079
http_request_seconds_max{application="order-service",ip="10.100.0.4",uri="/api/v1/order/create"} 0.948
http_request_seconds_max{application="order-service",ip="10.100.0.4",uri="/api/v1/order/query-detail"} 0.039
http_request_seconds_max{application="user-service",ip="10.100.0.1",uri="/api/v1/user/login"} 0.294
http_request_seconds_max{application="user-service",ip="10.100.0.1",uri="/api/v1/user/user-info"} 0.026
http_request_seconds_max{application="user-service",ip="10.100.0.2",uri="/api/v1/user/login"} 0.372
http_request_seconds_max{application="user-service",ip="10.100.0.2",uri="/api/v1/user/user-info"} 0.078
上面的数据乱了点,我们挑其中一个序列出来看:

我们可以看到,一个 summary 类型包含好几个时间序列,另外还有一个 gauge 类型的时间序列。
我们分别来看:
http_request_seconds{quantile="0.9"},这个记录的是当前的 P90 数据
http_request_seconds{quantile="0.99"},这个记录的是当前的 P99 数据
http_request_seconds_count:请求次数的总和,它和我们前面介绍 counter 类型的时候的 http_request_total 其实就是一个东西,记录累计访问次数。
http_request_seconds_sum:响应时间的总和,单位是秒,对接口的每次访问都会增加这个值,也是一个 counter 类型。
http_request_seconds_max:这个更好理解了,就是记录最大响应时间,它是 gauge 类型。
summary 数据计算细节
下面我们要来说一下 summary 的数据计算原理,这样有助于帮助我们理解它,并知道它适用的场景以及它的不足之处。
其实我们只需要知道分位数是怎么计算的就行了,至于 http_request_seconds_count、http_request_seconds_sum 和 http_request_seconds_max,这个非常简单,我们前面已经介绍过 counter 和 gauge 了。
下面介绍 P90 和 P99 是怎么计算出来的,也就是下面这两个数值怎么得出来:
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create",quantile="0.9"} 0.788529152
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create",quantile="0.99"} 0.788529152对于每个 summary 时间序列,micrometer 内部维护了 3 个时间窗口,每个窗口 1 分钟,轮转使用。
还记得我一开始做的配置吗?就是用在这个地方的。
management.metrics.distribution.buffer-length.[http.request]=3 management.metrics.distribution.expiry.[http.request]=1m
在开始的时候,先使用 0 号窗口,每次接口请求的耗时数据都扔到这个窗口里面,如果此时 prometheus 来拉取数据,那就从 0 号窗口计算一下 P90 和 P99 返回。

下一分钟的时候,使用 1 号窗口:

此时如果 prometheus 来拉取,那么 micrometer 会聚合 0 号窗口和 1 号窗口,计算出 P90 和 P99。
再下一分钟,启用 2 号窗口:

再往后一分钟,就轮转重新使用 0 号窗口,先把里面的值清空再重新使用:

所以每次 prometheus 来拉取数据的时候,其实 micrometer 都是把 3 个窗口的数据进行聚合以后计算出 P90 和 P99 返回。
这里需要非常注意的一个点,这个 summary 数据是客户端计算出来的,仅代表当前实例的数据,所以 summary 数据不能跨实例聚合。
比如在机器 10.10.0.1 上,/order/query-order 的 P90 是 50ms,在 10.10.0.2 上,它的 P90 是150ms,我们是没法计算出这两个实例的综合 P90 的,想一想 P90 数据代表什么意思就知道为什么不能做到了。甚至它也不支持多个时间窗口聚合,比如计算某个接口 1h 的 P90。
类似的问题,需要使用 histogram 类型进行解决。但是 summary 依然有它的实用之处,因为它相比 histogram,需要消耗的资源更少。
summary 类型数据制图
虽然说 summary 不能用来计算某个接口最近 1h 的 P90 这类需求,但是有一类需求通常用 summary 就能很好满足了,比如我们经常只需要关注最慢的 50 个接口:
topk(50,
max by (uri)
(http_request_seconds{application="order-service", quantile="0.9"})
)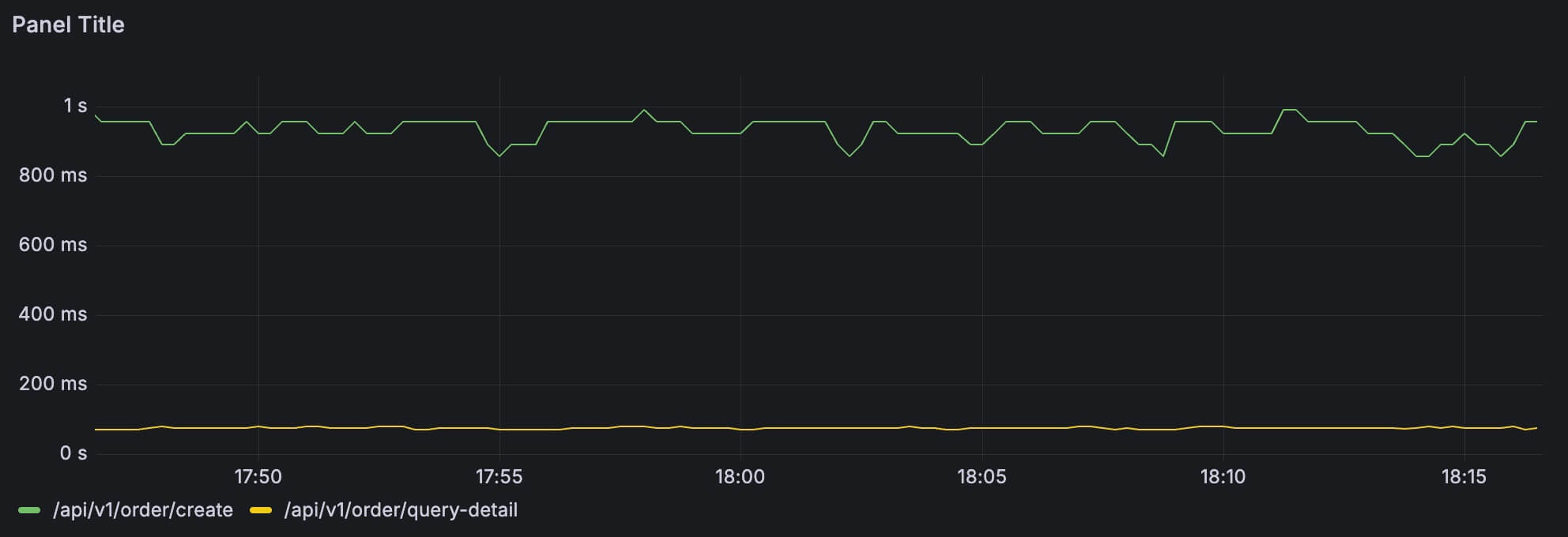
因为我就两个接口,top 50 没什么意义,你们可以在实际的环境中试试。
另外就是前面说过了,summary 额外提供了 count、sum、max 这三个数据,那么就能很好地满足诸如接口平均响应时间这种需求:
sum(increase(http_request_seconds_sum{application='order-service'}[2m]))by(uri)
/ sum(increase(http_request_seconds_count{application='order-service'}[2m]))by(uri)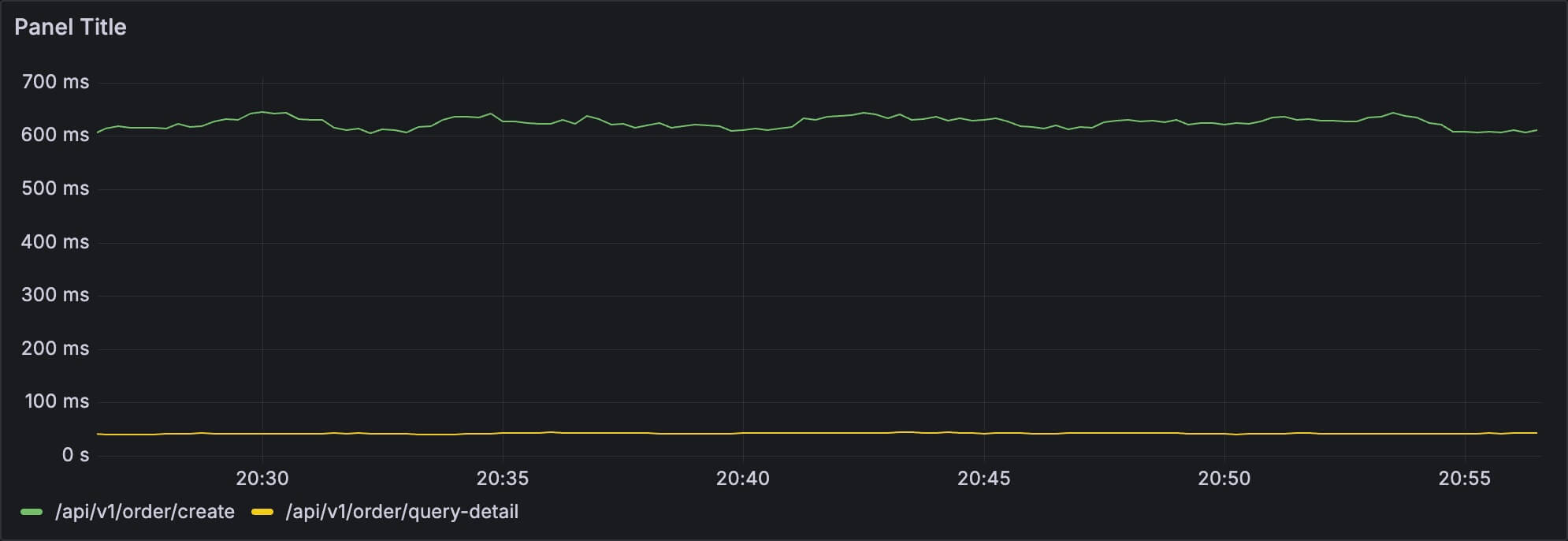
这个非常简单,就是利用过去 2 分钟耗时的总和除以 2 分钟内的总访问次数。
限于篇幅,max 这种 gauge 数据就不再展示了,过于简单。
我们再简单讨论下滑动时间窗口的数量,以及每个窗口的长度怎么配置。
如果我们想要快速检测到变化,那么可以考虑缩短每个窗口的时长,此时要相应增加窗口数量,以确保有足够的数据采样,比如:
management.metrics.distribution.buffer-length=5
management.metrics.distribution.expiry=30s而如果我们只是需要关注长期趋势,不需要对短期波动那么敏感,那么可以考虑降低窗口数量,增加窗口时长,比如:
management.metrics.distribution.buffer-length=2
management.metrics.distribution.expiry=5m由于我们减少了窗口数量,所以可以降低一些内存使用。
再回头看 summary 数据类型,如果我们把下面这种 P90、P99 的时间序列看成是 gauge 类型,每个值都代表那个时间点的“状态”,是不是就容易理解多了。
http_request_seconds{application="order-service",ip="10.100.0.3",uri="/api/v1/order/create",quantile="0.9"} 0.788529152Histogram 类型
前面介绍完了 summary,我们再介绍 histogram 就会好理解很多,它就是用来解决 summary 的不足的,因为 summary 没法做多实例聚合和多时间窗口聚合。
summary 主要使用的是客户端的资源来计算结果,而 histogram 使用的是服务端计算,客户端只负责上报数据。
首先,我们来看它的配置:
# 使用 histogram 类型,而不是 summary 类型
management.metrics.distribution.percentiles-histogram.[http.server.requests]=true
management.metrics.distribution.minimum-expected-value.[http.server.requests]=200ms
management.metrics.distribution.maximum-expected-value.[http.server.requests]=1s根据这个配置,我使用下面这行测试代码跑一些测试数据:
Metrics.timer("http.request", "uri", "/api/v1/user/test")
.record(RandomUtils.nextInt(300, 2000), TimeUnit.MILLISECONDS);这里模拟接口 /api/v1/user/test 的 RT 在 300ms-2000ms 之间,我们跑 100 次得到下面的结果:
# HELP http_request_seconds
# TYPE http_request_seconds histogram
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.2"} 0
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.20132659"} 0
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.223696211"} 0
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.246065832"} 0
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.268435456"} 0
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.357913941"} 6 # 有 6 次请求低于 357ms
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.447392426"} 10 # 有 10 次请求低于 447ms
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.536870911"} 14
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.626349396"} 21
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.715827881"} 25
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.805306366"} 29
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.894784851"} 33
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.984263336"} 38
http_request_seconds_bucket{uri="/api/v1/user/test",le="1.0"} 39 # 有 39 次请求低于 1s
http_request_seconds_bucket{uri="/api/v1/user/test",le="+Inf"} 100
http_request_seconds_count{uri="/api/v1/user/test"} 100
http_request_seconds_sum{uri="/api/v1/user/test"} 119.601
# HELP http_request_seconds_max
# TYPE http_request_seconds_max gauge
http_request_seconds_max{uri="/api/v1/user/test"} 1.997这里设置了 15 个桶,le 分别为 0.2, 0.20132659, 0.223696211, ..., 1.0, +Inf。
le 是 less than or equal to 的缩写,每个桶是一个 counter,用于记录 RT 小于等于该值的数量。比如某次请求的 RT 是 500ms,那么前面的几个桶不用动,从 le="0.536870911" 开始的后面所有的桶,都需要增加 1。
第一个桶的 le 是 "0.2", 最后两个桶的 le 是 "1.0" 和 "+Inf",这个是因为我们配置了 minimum 和 maximum,这两个值会影响数据结果的精度以及桶的数量。
下面我简单列一下 minimum 和 maximum 的值,对桶数量的影响:
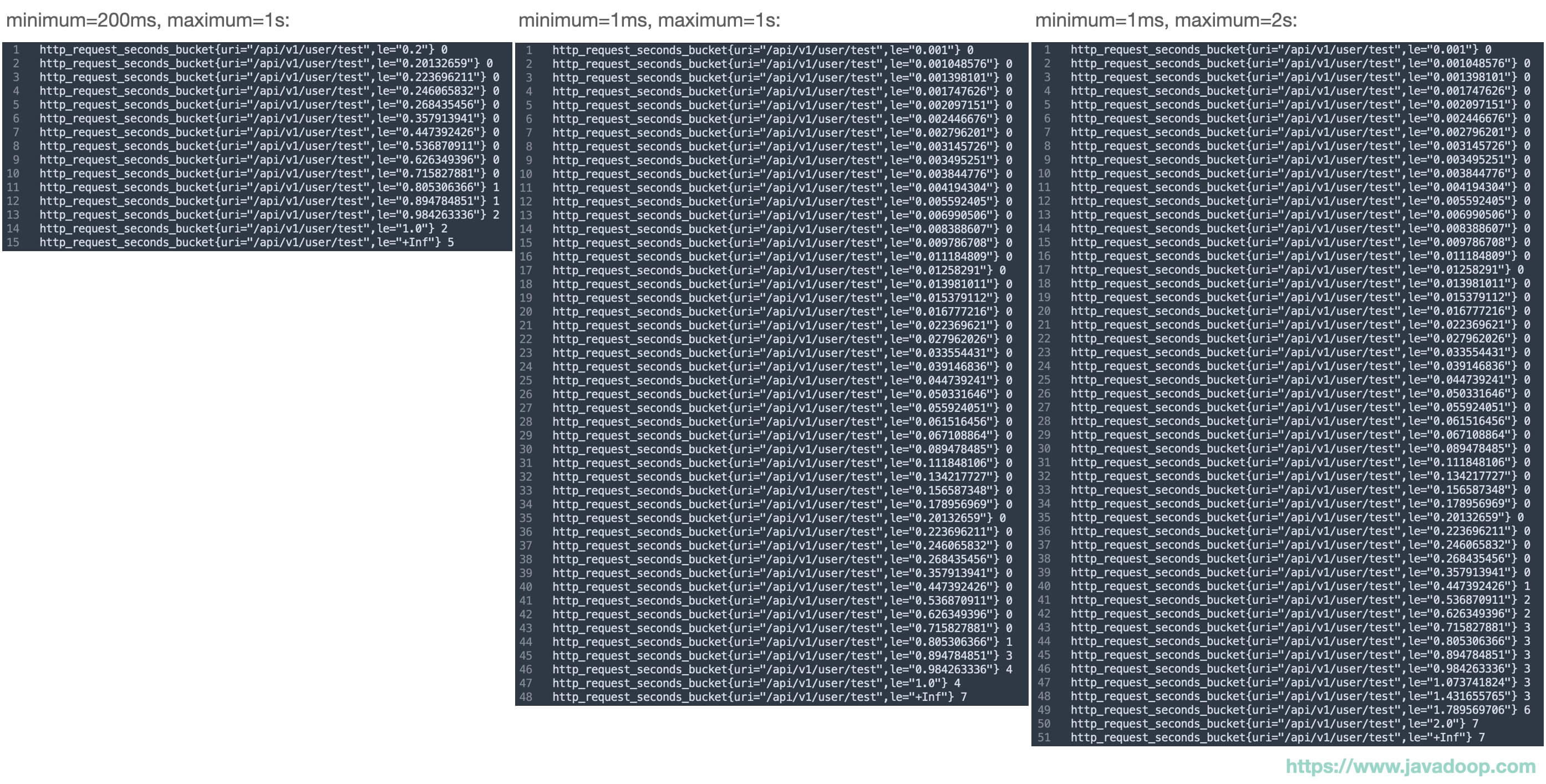
如果你的时间序列非常多的话,是需要考虑它们对服务端的性能消耗的,比如上面这个图中 200ms-1s 的设置只需要 15 个桶就可以了,但是使用 1ms-1s 的设置,需要 48 个桶,
对于单个桶内部,prometheus 使用线性插值的方式来处理,举个例子:
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.894784851"} 33
http_request_seconds_bucket{uri="/api/v1/user/test",le="0.984263336"} 38我从上面取了两行相邻的数据下来,根据前面说的,我们可以知道,有 38 - 33 = 5 个请求落在了 (0.894784851, 0.984263336] 之间,但是具体落在哪里,这个信息 prometheus 是不知道的,对于 prometheus 来说,它是处理成让这 5 个值均匀分布在这个区间里面,这样就可以算 percentile 数据了。
到这里,基本上就清楚了 histogram 计算分位数的原理了,它就是根据各个桶里面的样本数量来计算的。
Histogram 类型制图
从前面的例子中,我们可以看到 histogram 和 summary 一样,也包含了下面几个指标:
http_request_seconds_count{uri="/api/v1/user/test"} 100
http_request_seconds_sum{uri="/api/v1/user/test"} 119.601
http_request_seconds_max{uri="/api/v1/user/test"} 1.997它们的命名规则是一致的,这里也是两个 counter 和一个 gauge,所以诸如接口 QPS、平均访问时间、最大访问时间这类图,能非常容易做出来,这里就不再演示了。
我们需要了解的,无非就是怎么做分位数图就可以了,比如 P95:
histogram_quantile(0.95,
sum(rate(http_request_seconds_bucket[5m])) by (le, uri)
) * 1000这里先使用 sum 函数根据 le 和 uri 先聚合一下,然后在这个基础上取 P95,这样就能得到各个接口的 P95 了。
小结
本文主要源自于团队内技术分享,希望这类文章可以帮助你解决一些日常碰到的疑惑。
对于业务开发者来说,平时更多的只是看看监控大盘,但是不太了解内部机制,很多时候可能想知道这个图表的数据是怎么算出来的,或者想要自己实现一些业务监控,希望本文能提供一些帮助。
如果只是为了配置各种中间件的监控图表,从 Grafana 社区就可以拿到大量的模板,而不需要大家自己重复造轮子。
欢迎大家留言区讨论交流,我会尽量解答大家的疑问。
(全文完)
0 条评论